

Algoritma machine learning kini menjadi tulang punggung berbagai inovasi teknologi yang mendorong efisiensi dan ketepatan dalam pengambilan keputusan bisnis.
Dengan kemampuan untuk memproses data dalam jumlah besar dan mengenali pola yang kompleks, algoritma-algoritma ini memungkinkan perusahaan untuk membuat prediksi yang lebih akurat, meningkatkan personalisasi layanan, serta mengotomatisasi proses yang sebelumnya memerlukan campur tangan manusia.
Di tengah banyaknya jenis algoritma yang tersedia, memahami algoritma machine learning yang paling populer menjadi kunci untuk memilih solusi yang tepat sesuai kebutuhan bisnis.
Artikel ini akan mengulas secara mendalam algoritma-algoritma tersebut, alasan mengapa pemahaman terhadap algoritma populer sangat penting, serta contoh penerapannya dalam berbagai sektor industri.
Apa itu Machine Learning Algorithms?
Algoritma machine learning adalah teknik komputasional yang dirancang untuk membuat prediksi, keputusan, atau klasifikasi berdasarkan data.
Algoritma ini belajar dari data historis, mengidentifikasi pola, dan menerapkan informasi yang dipelajari ini ke kumpulan data baru. Intinya, mereka membangun model yang dapat secara otomatis meningkatkan kinerja melalui pengalaman, tanpa diprogram eksplisit untuk setiap tugas tertentu.
Kemampuan untuk belajar dan beradaptasi ini membuat machine learning sangat berharga di berbagai bidang seperti keuangan, kesehatan, pemasaran, dan lainnya.
Jenis-Jenis Algoritma Machine Learning yang Populer dan Penerapannya
Machine learning mencakup berbagai pendekatan dalam membangun model prediktif berdasarkan data. Untuk membantu memahami perbedaan dan kegunaan dari masing-masing pendekatan, algoritma machine learning umumnya dibagi ke dalam tiga kategori besar, yakni Supervised Learning, Unsupervised Learning, dan Reinforcement Learning.
Masing-masing memiliki karakteristik, keunggulan, serta penerapan yang berbeda tergantung pada tujuan dan jenis data yang dimiliki.
1. Supervised Learning
Supervised learning adalah pendekatan di mana model dilatih menggunakan data yang sudah berlabel, artinya setiap data input memiliki output yang sudah diketahui. Tujuannya adalah agar model mampu memprediksi output dari data baru yang belum pernah dilihat sebelumnya.
Beberapa algoritma populer di kategori ini antara lain:
- Linear Regression: Digunakan untuk memprediksi nilai numerik (seperti harga atau suhu) berdasarkan hubungan antara variabel input dan output.
- Logistic Regression: Cocok untuk memprediksi hasil biner seperti ya/tidak atau 0/1, misalnya dalam kasus deteksi email spam.
- Decision Tree: Menyusun keputusan dalam bentuk pohon berdasarkan serangkaian kondisi; mudah dipahami dan diinterpretasikan.
- Random Forest: Menggabungkan banyak pohon keputusan untuk meningkatkan akurasi dan stabilitas prediksi.
- Support Vector Machine (SVM): Digunakan untuk memisahkan data ke dalam dua kelas dengan margin maksimal.
- Naive Bayes: Klasifikasi berbasis probabilitas yang sederhana namun efektif, sering digunakan dalam analisis teks.
Pendekatan supervised sangat umum digunakan di dunia bisnis untuk prediksi permintaan, deteksi penipuan, hingga rekomendasi produk.
2. Unsupervised Learning Algorithms
Unsupervised learning algorithms adalah salah satu jenis metode dalam machine learning yang digunakan untuk menemukan pola tersembunyi atau struktur dalam data tanpa adanya label atau target output yang telah ditentukan sebelumnya. Berbeda dengan supervised learning, di mana model dilatih menggunakan data yang sudah diberi label, unsupervised learning hanya menggunakan data mentah untuk melakukan analisis.
Tujuan utama dari Unsupervised learning algorithms adalah untuk memahami struktur data yang mendasarinya dan mengidentifikasi pola yang mungkin tidak terlihat secara langsung. Teknik ini sangat berguna ketika kita memiliki data yang besar dan kompleks namun tidak memiliki informasi label yang jelas. Dalam banyak kasus, pembelajaran tanpa pengawasan digunakan untuk pengelompokan data, pengurangan dimensi, dan deteksi anomali.
A. K-Means Clustering
K-means clustering adalah salah satu algoritma pengelompokan (clustering) yang paling sederhana dan populer. Algoritma ini bertujuan untuk membagi dataset ke dalam K kelompok (cluster) berdasarkan kedekatan data satu sama lain. Setiap data akan ditempatkan dalam kelompok dengan centroid (pusat kelompok) terdekat. Proses ini diulangi sampai posisi centroid tidak berubah secara signifikan.
Langkah-langkah
Proses K-Means Clustering dapat dibagi menjadi beberapa langkah utama sebagai berikut:
- Inisialisasi
Pada langkah pertama, tentukan jumlah cluster (K) yang diinginkan. Kemudian, pilih K titik sebagai pusat awal (centroid). Pemilihan centroid awal dapat dilakukan secara acak atau menggunakan metode tertentu seperti K-Means++ untuk memastikan penyebaran yang lebih baik. - Asosiasi
Setiap data dalam dataset akan diasosiasikan dengan centroid terdekat. Kedekatan biasanya diukur menggunakan jarak Euclidean, meskipun metrik jarak lain juga dapat digunakan. - Pembaruan Centroid
Setelah semua data telah diasosiasikan dengan centroid terdekat, hitung ulang posisi centroid dengan mengambil rata-rata dari semua data yang termasuk dalam cluster tersebut. Posisi centroid baru ini akan menjadi pusat cluster yang diperbarui. - Iterasi
Langkah asosiasi dan pembaruan centroid akan diulang hingga posisi centroid tidak berubah secara signifikan atau mencapai jumlah iterasi maksimum yang telah ditentukan. Konvergensi biasanya dicapai ketika tidak ada perubahan berarti dalam posisi centroid. - Hasil Akhir
Setelah proses iterasi selesai, hasil akhirnya adalah K cluster dengan data yang telah terkelompokkan berdasarkan kedekatan.
Kelebihan dan Kekurangan K-Means Clustering
Kelebihan:
- Sederhana dan Cepat: Algoritma ini relatif mudah diimplementasikan dan cepat dalam komputasi, terutama untuk dataset yang besar.
- Efektif untuk Cluster Berbentuk Bulat: K-Means Clustering bekerja sangat baik ketika cluster memiliki bentuk yang bulat dan ukuran yang serupa.
- Skalabilitas: Algoritma ini dapat diskalakan dengan baik untuk dataset yang besar.
Kekurangan:
- Pemilihan K yang Sulit: Menentukan jumlah cluster (K) yang tepat seringkali sulit dan membutuhkan eksperimen atau metode evaluasi seperti Elbow Method.
- Sensitif terhadap Centroid Awal: Hasil akhir sangat bergantung pada pemilihan centroid awal, sehingga hasil dapat bervariasi.
- Tidak Efektif untuk Cluster dengan Bentuk yang Berbeda: K-Means Clustering kurang efektif untuk cluster dengan bentuk yang tidak bulat atau ukuran yang sangat berbeda.
- Tidak Menangani Outlier dengan Baik: Outlier dapat mempengaruhi posisi centroid secara signifikan, sehingga mempengaruhi hasil clustering.
Implementasi
Berikut adalah contoh sederhana implementasi K-Means Clustering menggunakan Python dan pustaka scikit-learn:
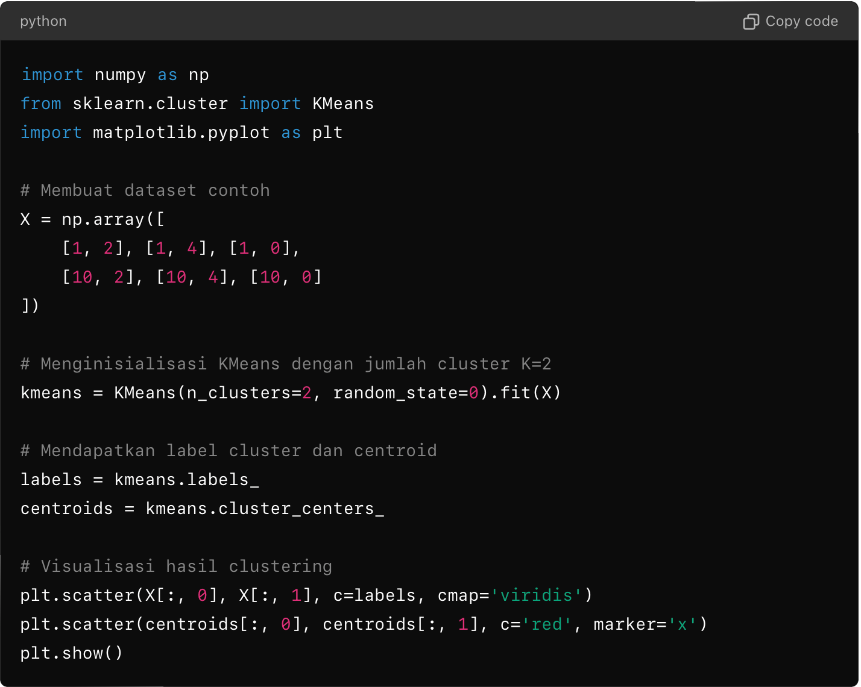
Dalam contoh di atas, kita membuat dataset sederhana dan menerapkan K-Means Clustering dengan dua cluster. Hasil clustering divisualisasikan dengan warna yang berbeda untuk setiap cluster dan centroid ditandai dengan ‘x’ merah.
B. Hierarchical Clustering
Hierarchical clustering adalah yang digunakan untuk mengelompokkan data berdasarkan hierarki atau tingkat. Algoritma ini membangun hierarki dari cluster yang dapat divisualisasikan dalam bentuk dendrogram, sebuah diagram pohon yang menunjukkan hubungan antar data dalam berbagai tingkat pengelompokan. Ada dua pendekatan utama dalam hierarchical clustering: agglomerative (bottom-up) dan divisive (top-down).
Jenis-jenis Hierarchical Clustering:
1. Agglomerative Hierarchical Clustering
Agglomerative clustering adalah metode yang lebih umum digunakan di antara keduanya. Algoritma ini dimulai dengan setiap data sebagai cluster tersendiri dan secara bertahap menggabungkan dua cluster terdekat hingga semua data tergabung dalam satu cluster besar. Berikut adalah langkah-langkah utama dalam agglomerative hierarchical clustering:
- Inisialisasi
Setiap data diperlakukan sebagai satu cluster individual. - Penghitungan Jarak
Hitung jarak antar cluster menggunakan metrik jarak seperti Euclidean, Manhattan, atau lainnya. Pilih dua cluster yang paling dekat satu sama lain. - Penggabungan Cluster
Gabungkan dua cluster terdekat menjadi satu cluster baru - Pembaruan Jarak
Hitung ulang jarak antara cluster baru dengan cluster lainnya. - Iterasi
Ulangi langkah penghitungan jarak, penggabungan cluster, dan pembaruan jarak sampai semua data tergabung dalam satu cluster besar.
2. Divisive Hierarchical Clustering
Divisive clustering adalah kebalikan dari agglomerative clustering. Algoritma ini dimulai dengan satu cluster besar yang mencakup semua data dan secara bertahap membagi cluster menjadi sub-cluster yang lebih kecil hingga setiap data menjadi cluster individual. Meskipun jarang digunakan dibandingkan dengan agglomerative clustering, pendekatan ini bisa efektif dalam situasi tertentu.
Metode Penghitungan Jarak Antar Cluster
- Single Linkage
Single linkage mengukur jarak antara dua cluster sebagai jarak minimum antara dua titik data dari masing-masing cluster. Metode ini cenderung menghasilkan cluster yang berbentuk rantai. - Complete Linkage
Complete linkage mengukur jarak antara dua cluster sebagai jarak maksimum antara dua titik data dari masing-masing cluster. Metode ini cenderung menghasilkan cluster yang lebih kompak dan bulat. - Average Linkage
Average linkage mengukur jarak antara dua cluster sebagai rata-rata jarak antara semua pasangan titik data dari masing-masing cluster. - Ward’s Method
Ward’s method mengukur jarak antara dua cluster sebagai peningkatan jumlah kuadrat kesalahan (sum of squared errors, SSE) yang dihasilkan dari penggabungan dua cluster. Metode ini cenderung menghasilkan cluster dengan ukuran yang seragam.
Visualisasi dengan Dendrogram
Dendrogram adalah alat visual yang penting dalam hierarchical clustering. Dendrogram menunjukkan bagaimana data di kelompokkan pada berbagai tingkat hierarki. Sumbu horizontal dendrogram mewakili data, sementara sumbu vertikal menunjukkan jarak atau perbedaan antar cluster. Dengan memotong dendrogram pada tingkat tertentu, kita dapat menentukan jumlah cluster yang diinginkan.
Kelebihan dan Kekurangan Hierarchical Clustering
Kelebihan:
- Tidak Perlu Menentukan Jumlah Cluster: Hierarchical clustering tidak memerlukan penentuan jumlah cluster (K) di awal.
- Visualisasi Hierarki: Dendrogram memberikan visualisasi yang jelas tentang hierarki dan struktur data.
- Fleksibilitas: Dapat digunakan untuk data dalam berbagai bentuk dan distribusi.
Kekurangan:
- Kompleksitas Komputasi: Hierarchical clustering memiliki kompleksitas komputasi yang lebih tinggi dibandingkan dengan algoritma clustering lainnya, terutama untuk dataset besar.
- Sensitif terhadap Noisy Data dan Outliers: Data yang berisik atau outliers dapat mempengaruhi hasil clustering secara signifikan.
- Tidak Dapat Diulang: Penggabungan atau pemisahan yang dilakukan di awal tidak dapat diubah, yang dapat menyebabkan hasil yang tidak optimal.
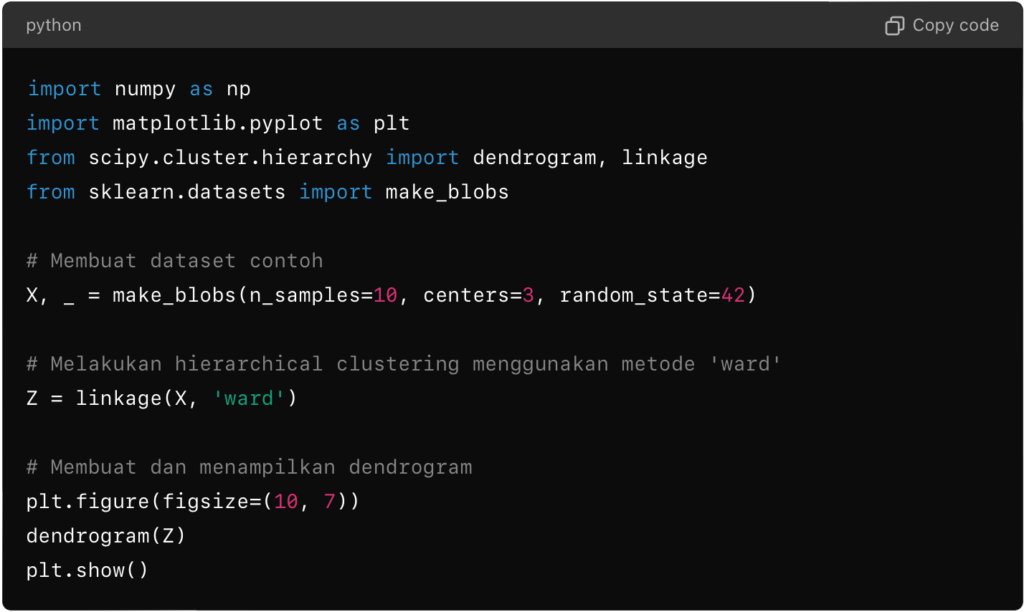
Implementasi
Berikut adalah contoh sederhana implementasi agglomerative hierarchical clustering menggunakan Python dan pustaka scikit-learn:
C. Principal Component Analysis (PCA)
Principal Component Analysis (PCA) adalah teknik statistik yang digunakan untuk mengurangi dimensi data dengan cara mentransformasi variabel asal menjadi variabel baru yang disebut komponen utama (principal components). PCA bertujuan untuk mengurangi jumlah variabel tanpa mengorbankan terlalu banyak informasi, memungkinkan analisis data yang lebih sederhana dan efisien. Teknik ini sangat berguna dalam visualisasi data dan pra-pemrosesan untuk algoritma machine learning.
Konsep Dasar PCA
PCA bekerja dengan mengidentifikasi arah utama (komponen utama) di mana variasi dalam data terbesar terjadi. Komponen-komponen ini adalah kombinasi linear dari variabel asal dan saling ortogonal satu sama lain, sehingga tidak ada redundansi informasi di antara mereka. PCA berusaha untuk mempertahankan sebanyak mungkin variasi dalam data asli dengan menggunakan lebih sedikit variabel.
Langkah-langkah PCA
- Standarisasi Data
Langkah pertama dalam PCA adalah menstandarisasi data sehingga setiap variabel memiliki rata-rata nol dan deviasi standar satu. Hal ini penting karena PCA sensitif terhadap skala variabel. Data yang tidak distandarisasi dapat menyebabkan komponen utama didominasi oleh variabel dengan skala lebih besar. - Membuat Matriks Kovarians
Setelah data distandarisasi, langkah berikutnya adalah membuat matriks kovarians untuk mengidentifikasi hubungan antara variabel. Matriks kovarians mengukur bagaimana dua variabel berubah bersama-sama - Menghitung Vektor Eigen dan Nilai Eigen
Dari matriks kovarians, hitung vektor eigen (eigenvectors) dan nilai eigen (eigenvalues). Vektor eigen menentukan arah komponen utama, sedangkan nilai eigen menunjukkan besar variasi sepanjang komponen tersebut - Menyortir dan Memilih Komponen Utama
Vektor eigen dan nilai eigen disortir berdasarkan nilai eigen dari yang terbesar ke yang terkecil. Komponen utama dipilih berdasarkan jumlah total variasi yang ingin dipertahankan. Biasanya, komponen utama dengan nilai eigen terbesar yang mempertahankan 95% hingga 99% variasi dipilih - Membuat Matriks Proyeksi
Langkah terakhir adalah membuat matriks proyeksi menggunakan vektor eigen yang dipilih dan mentransformasi data asli ke dalam ruang komponen utama. Data baru ini memiliki dimensi yang lebih rendah tetapi tetap mempertahankan sebagian besar informasi dari data asli.
Kelebihan dan Kekurangan PCA
Kelebihan:
- Pengurangan Dimensi: PCA secara efektif mengurangi jumlah variabel, membuat analisis data lebih sederhana dan efisien.
- Menghilangkan Redundansi: Komponen utama saling ortogonal, sehingga tidak ada redundansi informasi.
- Meningkatkan Kinerja Algoritma: PCA dapat meningkatkan kinerja algoritma machine learning dengan mengurangi noise dan overfitting.
- Visualisasi Data: PCA memungkinkan visualisasi data berdimensi tinggi dalam 2D atau 3D, memudahkan pemahaman pola dalam data.
Kekurangan:
- Asumsi Linearitas: PCA mengasumsikan hubungan linear antara variabel, sehingga mungkin tidak efektif untuk data dengan hubungan non-linear.
- Interpretasi Sulit: Komponen utama adalah kombinasi linear dari variabel asal, yang sering kali sulit untuk diinterpretasikan secara langsung.
- Sensitif terhadap Skala: PCA sensitif terhadap skala variabel, sehingga standarisasi data sangat penting.
- Kehilangan Informasi: Meskipun PCA mempertahankan sebanyak mungkin variasi, beberapa informasi tetap hilang dalam proses pengurangan dimensi.
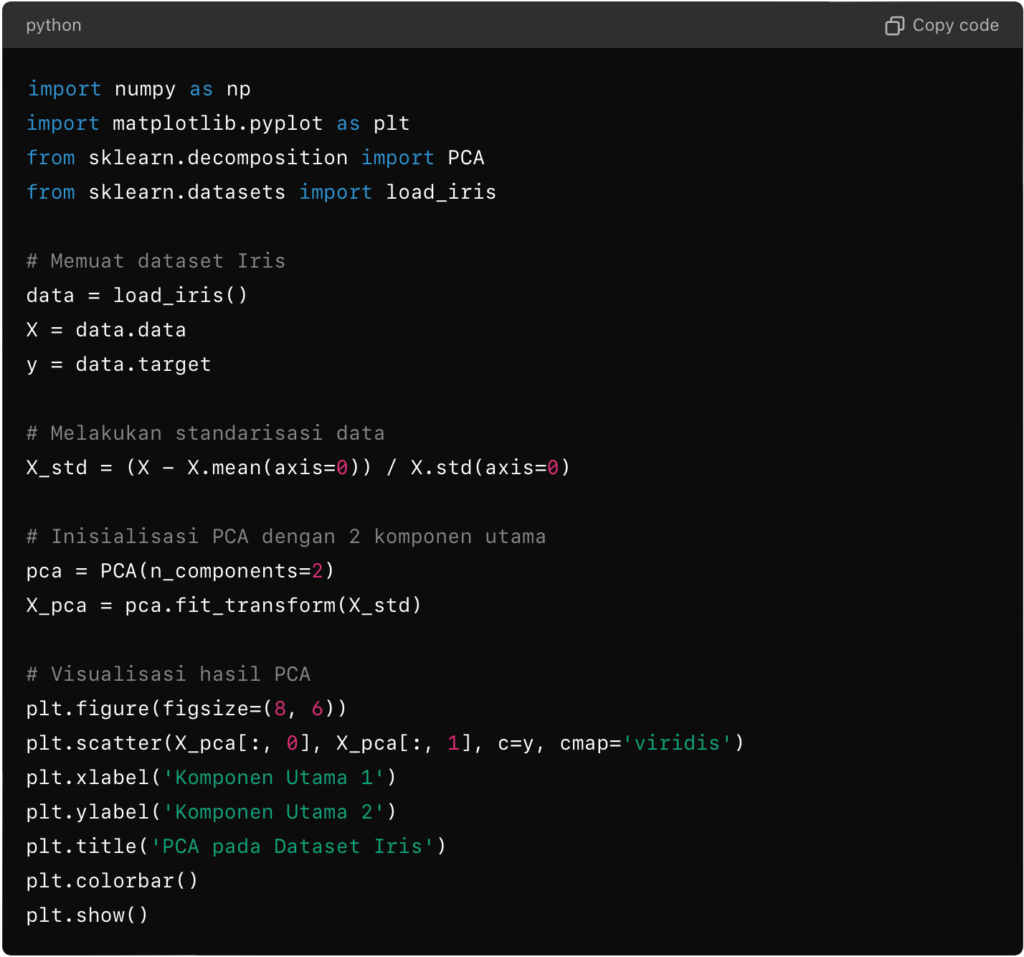
Implementasi
Berikut adalah contoh implementasi PCA menggunakan Python dan pustaka scikit-learn:
Aplikasi PCA
PCA memiliki berbagai aplikasi dalam berbagai bidang, termasuk:
- Pengolahan Citra: Mengurangi dimensi citra untuk kompresi atau pengenalan pola.
- Genomika: Menganalisis data genomik yang berdimensi tinggi.
- Keuangan: Mengidentifikasi faktor utama yang mempengaruhi pasar saham.
- Pengolahan Sinyal: Mengurangi noise dalam sinyal audio atau video.
D. t-Distributed Stochastic Neighbor Embedding (t-SNE)
t-Distributed Stochastic Neighbor Embedding (t-SNE) adalah teknik yang digunakan untuk mengurangi dimensi data dengan cara yang memungkinkan visualisasi data berdimensi tinggi dalam dua atau tiga dimensi. t-SNE dikembangkan oleh Laurens van der Maaten dan Geoffrey Hinton, dan sangat populer dalam bidang machine learning dan data science karena kemampuannya mengungkapkan struktur internal dari data yang kompleks.
Konsep Dasar t-SNE
t-SNE bekerja dengan memetakan data dari ruang berdimensi tinggi ke ruang berdimensi rendah sambil mempertahankan hubungan jarak dekat antar titik data. Proses ini dilakukan dengan dua tahap utama:
- Pemetaan Probabilistik di Ruang Berdimensi Tinggi
t-SNE pertama-tama menghitung probabilitas bahwa dua titik data dalam ruang berdimensi tinggi adalah tetangga dekat. Probabilitas ini dihitung menggunakan distribusi Gaussian, di mana jarak dekat antar titik data diberikan probabilitas yang tinggi dan jarak jauh diberikan probabilitas yang rendah. - Pemetaan Probabilistik di Ruang Berdimensi Rendah
t-SNE kemudian mencoba menemukan representasi data dalam ruang berdimensi rendah yang mempertahankan probabilitas tetangga dekat dari ruang berdimensi tinggi. Distribusi t-Student digunakan dalam ruang berdimensi rendah untuk menghitung probabilitas antar titik data. Distribusi t-Student dipilih karena memiliki ekor yang lebih berat dibandingkan dengan distribusi Gaussian, sehingga lebih efektif dalam menangani outlier.
Langkah-langkah
Proses t-SNE dapat dijelaskan melalui langkah-langkah berikut:
1. Membentuk Distribusi di Ruang Berdimensi Tinggi
Untuk setiap pasangan titik data i dan , t-SNE menghitung probabilitas pij bahwa titik i akan memilih titik j sebagai tetangganya, menggunakan distribusi Gaussian yang terpusat pada titik ii. Probabilitas ini dihitung sebagai berikut
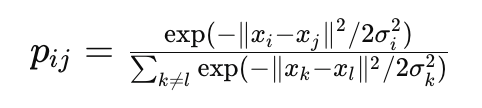
di mana σi adalah parameter skala yang disesuaikan untuk memastikan distribusi probabilitas bersifat simetris.
2. Membentuk Distribusi di Ruang Berdimensi Rendah
Untuk setiap pasangan titik data į dan j, t-SNE menghitung probabilitas qij bahwa titik į akan memilih titik j sebagai tetangganya dalam ruang berdimensi rendah, menggunakan distribusi t-Student:
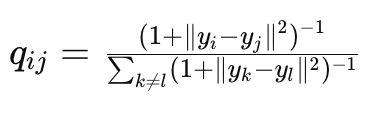
3. Meminimalkan Divergensi Kullback-Leibler (KL)
t-SNE meminimalkan perbedaan antara distribusi probabilitas di ruang berdimensi tinggi dan rendah dengan meminimalkan divergensi Kullback-Leibler (KL):
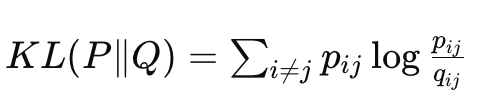
Optimasi ini dilakukan menggunakan metode gradien yang dipercepat.
Kelebihan dan Kekurangan t-SNE
Kelebihan:
- Kemampuan Visualisasi yang Baik: t-SNE sangat efektif untuk visualisasi data berdimensi tinggi dalam dua atau tiga dimensi, mengungkapkan pola dan struktur internal data.
- Menangani Data Kompleks: t-SNE dapat mengungkapkan kluster data yang kompleks dan non-linear yang mungkin tidak terlihat dengan teknik pengurangan dimensi lainnya.
- Mengatasi Masalah Overfitting: Dengan menggunakan distribusi t-Student, t-SNE lebih tahan terhadap outlier dibandingkan metode lain.
Kekurangan:
- Kompleksitas Komputasi: t-SNE memerlukan waktu komputasi yang cukup tinggi, terutama untuk dataset besar.
- Parameter Sensitif: Hasil t-SNE sangat dipengaruhi oleh parameter seperti perplexity, learning rate, dan iterasi, sehingga memerlukan penyesuaian parameter yang hati-hati.
- Tidak Reproducible: Hasil t-SNE bisa bervariasi antar pelatihan karena inisialisasi acak, sehingga sulit untuk mereproduksi hasil yang sama.
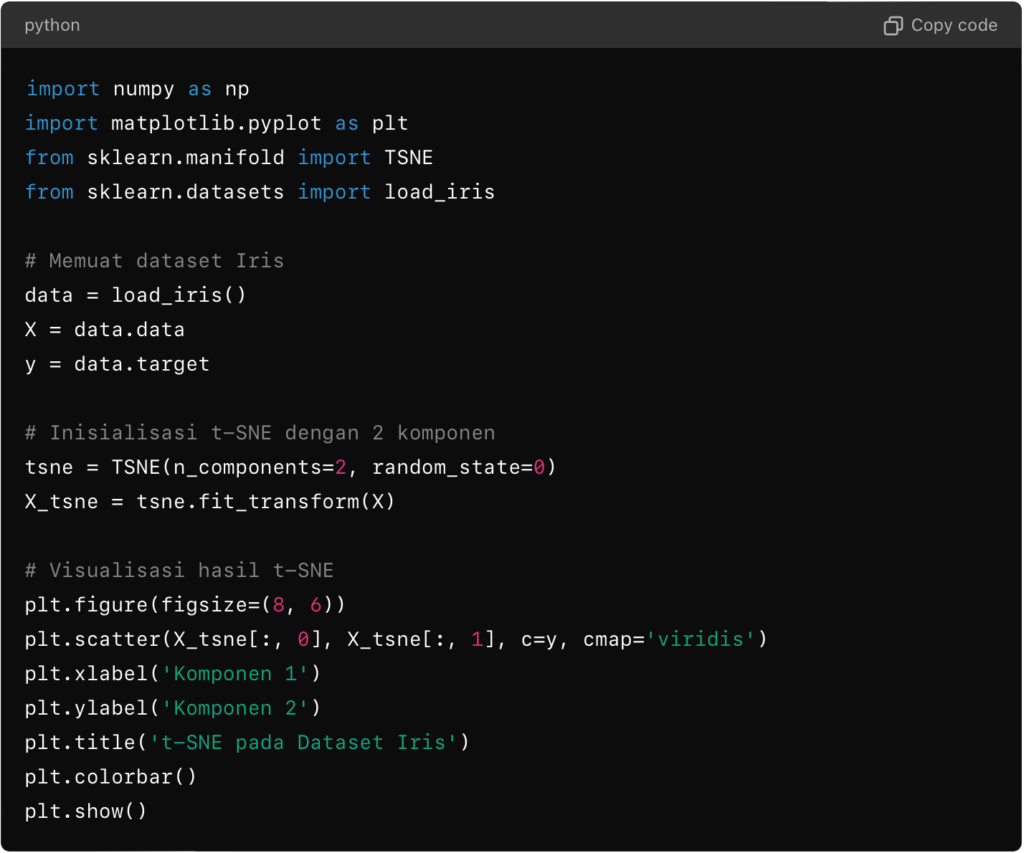
Implementasi
Berikut adalah contoh implementasi t-SNE menggunakan Python dan pustaka scikit-learn:
Aplikasi t-SNE
t-SNE memiliki berbagai aplikasi dalam berbagai bidang, termasuk:
- Visualisasi Data: Menyederhanakan visualisasi data berdimensi tinggi untuk analisis eksploratif.
- Pengenalan Pola: Mengidentifikasi kluster dan pola dalam data kompleks, seperti data genomik dan citra.
- Pra-pemrosesan Data: Mengurangi dimensi data sebelum diterapkan ke algoritma machine learning lain.
3. Reinforcement Learning Algorithms
Algoritma Reinforcement Learning (RL) adalah metode dalam kecerdasan buatan yang memungkinkan komputer atau agen untuk belajar dari pengalaman, mirip dengan cara manusia belajar melalui trial and error. Bayangkan saat Anda belajar bermain game. Awalnya, Anda mungkin tidak tahu apa yang harus dilakukan, tetapi seiring waktu, dengan mencoba berbagai aksi dan melihat hasilnya, Anda akan mulai memahami strategi yang efektif. Prinsip yang sama berlaku untuk RL.
Dalam RL, ada tiga komponen utama: agen, lingkungan, dan reward (hadiah). Agen, yang bisa berupa robot atau program komputer, ditempatkan dalam suatu lingkungan di mana ia harus membuat keputusan. Setiap kali agen melakukan aksi berdasarkan kondisi atau situasi saat ini (state), ia menerima umpan balik dari lingkungan dalam bentuk reward. Tujuan agen adalah memaksimalkan total reward yang diterimanya selama interaksi ini.
Misalnya, bayangkan agen sebagai robot yang harus menemukan jalan keluar dari labirin. Setiap langkah yang mendekatkannya ke pintu keluar dapat memberikan reward positif, sedangkan langkah menuju jalan buntu atau jebakan memberikan reward negatif. Agen akan menjelajahi berbagai rute, mencatat langkah-langkah yang membawa reward positif, dan akhirnya menemukan jalur optimal untuk keluar dari labirin.
Salah satu algoritma RL yang sederhana adalah Q-Learning. Dalam Q-Learning, agen menyimpan tabel bernama Q-Table, di mana setiap pasangan situasi dan tindakan diberikan nilai (Q-value) yang mencerminkan seberapa baik tindakan itu di masa depan. Agen terus memperbarui Q-Table ini berdasarkan pengalaman yang didapat dari setiap langkah. Misalnya, jika sebuah aksi menghasilkan hasil yang baik, Q-value untuk aksi tersebut akan meningkat.
Untuk situasi yang lebih kompleks, seperti bermain video game atau kendali robot yang rumit, algoritma yang lebih canggih seperti Deep Q-Networks (DQN) dapat digunakan. DQN menggabungkan Q-Learning dengan jaringan saraf (neural networks) untuk menangani dimensi dan kompleksitas yang lebih tinggi.
Secara keseluruhan, algoritma Reinforcement Learning seperti Q-Learning dan DQN menyediakan cara bagi komputer untuk belajar melalui pengalaman dan umpan balik, memungkinkan mesin untuk melakukan tugas-tugas kompleks secara mandiri dan efisien. Ini adalah bagian penting dari perkembangan kecerdasan buatan yang membuka jalan bagi berbagai aplikasi inovatif, mulai dari robotika hingga permainan video dan sistem rekomendasi.
Bagaimana Algoritma Machine Learning Bekerja?
Setelah mempelajari berbagai jenis algoritma pembelajaran mesin, penting untuk memahami bagaimana algoritma-algoritma tersebut bekerja.
Proses ini melibatkan beberapa langkah kunci, mulai dari pra-pemrosesan data hingga penyetelan hyperparameter. Dalam bagian ini, kita akan menjelaskan setiap langkah secara detail untuk memberikan gambaran yang komprehensif tentang bagaimana sebuah model pembelajaran mesin dikembangkan dan dioptimalkan.
A. Pra-pemprosesan Data
Pra-pemprosesan data adalah tahap awal yang sangat penting dalam pembelajaran mesin. Data mentah yang dikumpulkan seringkali mengandung noise, data yang hilang, atau format yang tidak sesuai.
Pada tahap ini, data diolah agar siap digunakan oleh model pembelajaran mesin. Langkah-langkah utama dalam pra-pemrosesan data meliputi:
- Pembersihan Data: Menghapus atau mengisi nilai yang hilang dan mengoreksi kesalahan dalam data.
- Transformasi Data: Mengubah data ke dalam format yang sesuai, seperti normalisasi atau standardisasi.
- Pengurangan Dimensi: Mengurangi jumlah fitur dalam data untuk mengurangi kompleksitas tanpa mengorbankan informasi penting.
B. Pelatihan Model
Pelatihan model adalah proses di mana algoritma pembelajaran mesin mempelajari pola dari data yang sudah di pra-proses. Proses ini melibatkan penggunaan data latih untuk mengajarkan model bagaimana membuat prediksi atau keputusan berdasarkan input data.
Tahapan dalam pelatihan model meliputi:
- Pemilihan Algoritma: Memilih algoritma pembelajaran mesin yang sesuai dengan jenis masalah dan data yang tersedia.
- Pemisahan Data: Membagi data menjadi set data latih dan set data uji untuk mengukur kinerja model.
- Pelatihan Algoritma: Menggunakan data latih untuk melatih model dengan cara mengoptimalkan parameter model untuk meminimalkan kesalahan prediksi.
C. Metrik Evaluasi
Setelah model dilatih, penting untuk mengevaluasi kinerjanya menggunakan matrik evaluasi. Metrik ini membantu mengukur seberapa baik model memprediksi data baru yang belum pernah dilihat.
Beberapa metrik evaluasi yang umum digunakan antara lain:
- Akurasi: Persentase prediksi yang benar dari total prediksi.
- Presisi dan Recall: Metrik yang digunakan untuk mengukur kinerja pada masalah klasifikasi.
- Mean Squared Error (MSE): Metrik yang sering digunakan untuk mengukur kesalahan pada model regresi.
D. Penyetelan Hyperparameter
Penyetelan hyperparameter adalah proses mengoptimalkan parameter-parameter yang tidak dapat dipelajari langsung dari data selama pelatihan. Hyperparameter mempengaruhi bagaimana model belajar dan performa akhirnya.
Beberapa teknik yang digunakan untuk penyetelan hyperparameter meliputi:
- Grid Search: Mencoba semua kombinasi hyperparameter dalam rentang tertentu dan memilih yang terbaik.
- Random Search: Memilih kombinasi hyperparameter secara acak untuk mengurangi waktu pencarian.
- Bayesian Optimization: Menggunakan metode probabilistik untuk menemukan kombinasi hyperparameter yang optimal secara lebih efisien.
Dengan memahami dan menerapkan langkah-langkah di atas, Anda dapat memastikan bahwa model pembelajaran mesin yang dibangun memiliki kinerja yang optimal dan dapat diandalkan untuk aplikasi dunia nyata.
BACA JUGA: Bagaimana Mengembangkan Software berbasis AI
Contoh Aplikasi dan Penerapan Algoritma Machine Learning
Algoritma machine learning telah merevolusi berbagai industri dengan kemampuan mereka untuk memproses data dalam jumlah besar dan memberikan hasil yang akurat dan efisien.
Beberapa aplikasi paling signifikan dari algoritma machine learning meliputi Natural Language Processing (NLP), Computer Vision, Recommender Systems, dan Fraud Detection. Berikut adalah penjelasan lebih lanjut mengenai aplikasi-aplikasi tersebut:
A. Natural Language Processing (NLP)
Natural Language Processing (NLP) adalah cabang dari machine learning yang berfokus pada interaksi antara komputer dan bahasa manusia. Algoritma NLP digunakan untuk berbagai aplikasi seperti pengenalan suara, analisis sentimen, penerjemahan otomatis, dan chatbots. Contohnya, algoritma NLP dapat menganalisis teks dari media sosial untuk mengidentifikasi sentimen pengguna tentang produk tertentu, atau membantu asisten virtual seperti Siri dan Alexa dalam memahami dan merespons perintah suara.
B. Computer Vision
Computer Vision adalah bidang machine learning yang memungkinkan komputer untuk memahami dan memproses informasi visual dari dunia sekitar. Aplikasi dari algoritma ini sangat luas, mulai dari pengenalan wajah dan objek hingga analisis citra medis.
Misalnya, dalam bidang kesehatan, algoritma computer vision digunakan untuk menganalisis gambar radiologi dan mendeteksi penyakit seperti kanker pada tahap awal, yang dapat meningkatkan peluang kesembuhan pasien. Di industri otomotif, algoritma ini digunakan dalam pengembangan mobil otonom yang dapat mengenali dan bereaksi terhadap rambu lalu lintas dan pejalan kaki.
C. Recommender Systems
Recommender Systems adalah salah satu aplikasi paling umum dari machine learning yang digunakan oleh berbagai platform online untuk memberikan rekomendasi yang dipersonalisasi kepada pengguna.
Contohnya, platform seperti Netflix dan YouTube menggunakan algoritma machine learning untuk menganalisis riwayat tontonan pengguna dan merekomendasikan konten yang serupa. Dalam e-commerce, algoritma ini membantu situs seperti Amazon untuk menyarankan produk berdasarkan perilaku belanja dan preferensi pengguna, yang pada akhirnya meningkatkan pengalaman pengguna dan penjualan.
D. Fraud Detection
Fraud Detection adalah aplikasi penting lainnya dari machine learning, terutama dalam industri keuangan. Algoritma machine learning dapat menganalisis pola transaksi dan mendeteksi aktivitas yang mencurigakan yang mungkin menunjukkan adanya penipuan.
Contohnya, kartu kredit atau sistem pembayaran online menggunakan algoritma ini untuk memantau dan mendeteksi transaksi yang tidak biasa atau berisiko tinggi, sehingga dapat mencegah kerugian finansial. Selain itu, algoritma machine learning juga digunakan untuk mengidentifikasi penipuan dalam klaim asuransi dan deteksi spam di layanan email.
Secara keseluruhan, aplikasi algoritma machine learning telah memberikan kontribusi besar dalam meningkatkan efisiensi dan akurasi di berbagai bidang. Dengan terus berkembangnya teknologi ini, kita dapat mengharapkan lebih banyak inovasi dan peningkatan dalam berbagai aspek kehidupan kita.
Contoh Studi Kasus Penerapan Machine Learning
A. Healthcare
- Diagnosa Penyakit dengan IBM Watson Health
IBM Watson Health menggunakan Machine Learning untuk menganalisis data medis yang besar dan memberikan diagnosa serta rekomendasi pengobatan. Di beberapa rumah sakit, Watson telah membantu dokter dalam mendiagnosis kanker dengan akurasi yang lebih tinggi dibandingkan metode tradisional, serta mempercepat proses diagnosa. - DeepMind’s AlphaFold
AlphaFold dari DeepMind menggunakan Machine Learning untuk memprediksi struktur protein dari urutan asam amino. AlphaFold berhasil memecahkan masalah lipatan protein yang telah menjadi tantangan besar dalam biologi selama beberapa dekade. Ini memberikan wawasan mendalam tentang berbagai penyakit dan pengembangan obat.
B. Finance
- Fraud Detection oleh PayPal
PayPal menggunakan Machine Learning untuk mendeteksi aktivitas penipuan dalam transaksi keuangan. Dengan menggunakan algoritma Machine Learning, PayPal mampu mengidentifikasi dan memblokir transaksi penipuan secara real-time, mengurangi kerugian finansial dan meningkatkan kepercayaan pengguna. - Portfolio Management dengan Betterment
Betterment menggunakan algoritma Machine Learning untuk memberikan saran investasi yang dipersonalisasi kepada pengguna. Sistem ini mampu menyesuaikan strategi investasi berdasarkan profil risiko individu dan perubahan pasar, yang telah menghasilkan pengembalian yang lebih baik dan mengoptimalkan portofolio pengguna.
C. Autonomous Vehicles
- Waymo (Google) Self-Driving Car
Waymo menggunakan Machine Learning untuk mengembangkan teknologi mobil otonom yang mampu beroperasi tanpa campur tangan manusia. Mobil Waymo telah menjalani jutaan mil pengujian di jalan umum dengan catatan keselamatan yang mengesankan, dan saat ini sedang diuji coba untuk layanan ride-hailing di beberapa kota di Amerika Serikat. - Tesla Autopilot
Tesla Autopilot menggunakan algoritma Machine Learning untuk memberikan fitur pengemudian semi-otonom pada mobil mereka. Sistem ini telah meningkatkan pengalaman berkendara dengan fitur-fitur seperti pengemudian otomatis di jalan tol, perubahan jalur otomatis, dan parkir otomatis. Tesla terus memperbarui sistem ini melalui pembelajaran berkelanjutan dari data yang dikumpulkan dari jutaan mil yang ditempuh oleh mobil mereka.
Kesimpulan
Memahami berbagai jenis algoritma machine learning, baik supervised, unsupervised, maupun reinforcement learning merupakan langkah penting bagi siapa pun yang ingin memanfaatkan teknologi ini dalam pengambilan keputusan berbasis data.
Setiap algoritma memiliki karakteristik dan keunggulan masing-masing, tergantung pada jenis data dan tujuan analisisnya.
Bagi pelaku bisnis, pemahaman ini tidak hanya penting dari sisi teknis, tetapi juga strategis. Dengan memilih algoritma yang tepat, bisnis dapat mengoptimalkan proses internal, meningkatkan pengalaman pelanggan, hingga menciptakan produk dan layanan yang lebih cerdas.
Ingin menerapkan machine learning dalam bisnis Anda? Badr Interactive menyediakan layanan pengembangan solusi berbasis machine learning yang disesuaikan dengan kebutuhan spesifik bisnis Anda.
Mulai dari sistem rekomendasi, analisis prediktif, hingga automasi proses berbasis AI, kami siap membantu Anda merancang dan mengimplementasikan teknologi yang berdampak langsung terhadap efisiensi dan pertumbuhan bisnis.
Hubungi tim kami sekarang untuk konsultasi gratis dan temukan bagaimana machine learning bisa memberikan nilai lebih bagi bisnis Anda.
FAQs Mengenai Machine Learning Algorithms
A. Apa perbedaan antara Supervised Learning dan Unsupervised Learning?
Supervised Learning melibatkan melatih model pada data yang berlabel, di mana hasil atau variabel target diketahui. Model belajar untuk memprediksi target ini berdasarkan fitur input.
Contohnya termasuk tugas klasifikasi dan regresi. Sebaliknya, Unsupervised Learning berurusan dengan data yang tidak berlabel dan bertujuan untuk mengungkap pola tersembunyi atau struktur intrinsik dalam data. Clustering dan reduksi dimensi adalah aplikasi khas dari pembelajaran tidak terawasi.
B. Bagaimana neural network berbeda dari descision tree?
Neural network dan decision tree adalah pendekatan yang sangat berbeda untuk machine learning. Neural network terinspirasi oleh otak manusia dan terdiri dari lapisan node yang saling terhubung (neuron) yang dapat belajar representasi abstrak dari data.
Mereka sangat kuat untuk tugas-tugas yang melibatkan sejumlah besar data dan pola yang kompleks, seperti pengenalan gambar dan suara. Di sisi lain, decision tree adalah model yang sederhana dan mudah dibaca yang membagi data menjadi cabang-cabang berdasarkan nilai fitur, membuat keputusan di setiap node.
Mereka bekerja dengan baik untuk dataset yang lebih kecil dan memberikan aturan yang jelas dan mudah dipahami tetapi mungkin tidak berkinerja baik pada data yang kompleks dan berdimensi tinggi tanpa peningkatan seperti teknik ensemble.
C. Apa saja contoh nyata aplikasi Reinforcement Learning?
Reinforcement learning (RL) memiliki beberapa aplikasi nyata:
Gaming: Algoritma RL telah digunakan untuk menguasai permainan kompleks seperti Go (AlphaGo) dan berbagai video game, mengungguli pemain manusia.
Robotika: Robot menggunakan RL untuk belajar tugas secara mandiri, meningkatkan kemampuan mereka untuk menavigasi, memanipulasi objek, dan berinteraksi dengan manusia.
Kendaraan Otonom: Mobil self-driving menggunakan RL untuk membuat keputusan waktu nyata dalam lingkungan dinamis, memastikan navigasi yang aman dan efisien.
Kesehatan: Dalam perencanaan perawatan dan pengobatan pribadi, RL membantu dalam merancang strategi terbaik untuk perawatan pasien berdasarkan umpan balik yang sedang berlangsung.
Keuangan: RL digunakan untuk manajemen portofolio, perdagangan algoritmik, dan manajemen risiko, terus beradaptasi dengan perubahan pasar untuk mengoptimalkan pengembalian investasi.
Outline ini mencakup spektrum luas algoritma machine learning yang populer, cara kerjanya, aplikasi, tantangan, dan tren masa depan, memberikan pendekatan terstruktur untuk menyusun artikel panjang yang mendetail tentang topik ini.




